The past year has delivered remarkable advances in large language models. Reasoning capabilities have improved. Context windows have expanded. Multimodal inputs are becoming standard. On paper, AI agents have never looked more capable.
And yet, across enterprises, a familiar pattern persists.
AI agent pilots show promise—but production rollouts stall. Confidence erodes. Risk teams intervene. Human oversight quietly expands instead of shrinking.
The problem is not intelligence.
The real bottleneck in AI agent deployments today is evaluation—our ability to consistently determine whether an agent’s outputs are correct, trustworthy, and safe to act on in real-world conditions.
As models get smarter, the hardest question in production AI is no longer “Can the agent do this?”
It’s “How do we know it did the right thing—every time?”
What the Data Shows: Evaluation Remains Human-Centric
A recent large-scale study, Measuring Agents in Production (UC Berkeley / Stanford / IBM Research), examined 306 practitioners and 20 real production deployments across 26 industries. One finding stands out clearly:
Human judgment remains the backbone of production AI evaluation.
According to the study:
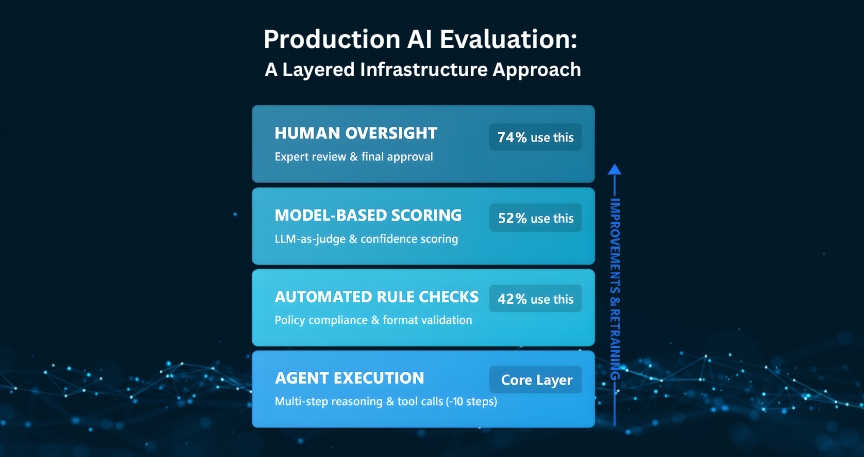
- 74% of production AI agents rely primarily on human-in-the-loop evaluation
- Formal benchmarks are rarely used in isolation
- “LLM-as-a-judge” techniques appear, but almost never alone
- Many teams define evaluation criteria only after deployment begins
This is not a failure of automation. It is a recognition of reality.
In enterprise environments—legal, compliance, customer support, healthcare, finance—correctness is rarely binary. Outputs must be accurate in context, defensible under scrutiny, and aligned with business and regulatory expectations. No static benchmark can fully capture that.
And yet, across enterprises, a familiar pattern persists.
AI agent pilots show promise—but production rollouts stall. Confidence erodes. Risk teams intervene. Human oversight quietly expands instead of shrinking.
The problem is not intelligence.
The real bottleneck in AI agent deployments today is evaluation—our ability to consistently determine whether an agent’s outputs are correct, trustworthy, and safe to act on in real-world conditions.
As models get smarter, the hardest question in production AI is no longer “Can the agent do this?”
It’s “How do we know it did the right thing—every time?”
Why Evaluation Is Harder Than Training
Evaluation has emerged as the limiting factor because it is structurally harder than model development in production settings.
Non-determinism
AI agents do not behave like traditional software. The same input can produce different outputs depending on context, prompts, or intermediate reasoning paths. This breaks conventional testing assumptions.
Contextual correctness
Many agent outputs are plausible but wrong. In regulated or high-stakes workflows, “almost correct” is often worse than obviously incorrect.
Lack of ground truth
Agent workflows—drafting, summarization, reasoning, decision support—rarely have a single correct answer. Evaluation becomes probabilistic, not absolute.
Silent failure modes
Errors often compound across steps. Failures surface downstream, disconnected from their root cause, making debugging and trust restoration difficult.
Evaluation failures rarely announce themselves. They accumulate quietly—until confidence breaks.
Evaluation Is Infrastructure, Not a Feature
In mature AI systems, evaluation cannot be treated as a final checkpoint or a QA task added before launch. It must be designed as infrastructure—a continuous layer that governs agent behavior throughout its lifecycle.
This is what we refer to as controlled autonomy:
agents operate freely within boundaries that are continuously evaluated, auditable, and expandable over time.
In production, evaluation answers four critical questions:
- When should the agent act?
- When should it pause?
- When should a human intervene?
- How do we explain what happened after the fact?
Effective evaluation infrastructure typically includes:
- Automated rule checks for policy, format, and safety
- Model-based scoring for confidence and consistency
- Human review triggered at defined escalation points
- Persistent audit trails capturing reasoning, actions, and outcomes
Evaluation doesn’t slow agents down—it defines the conditions under which safe acceleration is possible.
What Leaders Should Do Differently
For executives accountable for AI outcomes—not just innovation—the implications are clear.
First, budget for evaluation early. Counterintuitively, the most successful teams allocate 30–40% of agent development effort to evaluation systems, escalation logic, and auditability.
Second, treat human review as leverage, not cost. Well-designed human-in-the-loop systems amplify reliability and confidence rather than signaling immaturity.
Third, tie evaluation metrics to business outcomes, not model benchmarks. Risk reduction, QA coverage, regulatory defensibility, and operational trust matter more than marginal accuracy gains.
Finally, be skeptical of autonomy claims that aren’t paired with evaluation scaffolding. Autonomy without measurement isn’t progress—it’s exposure.
The fastest way to stall an AI program is to over-invest in intelligence and under-invest in evaluation.
A New Definition of Progress
As AI agents grow more capable, success will no longer be defined by how much autonomy a system claims to have. It will be defined by how well that autonomy is governed.
The next wave of enterprise AI advantage won’t come from who builds the smartest agents—but from who builds the most trustworthy ones in production, intelligence is table stakes.
Evaluation is the differentiator.
If you’re ready to move from pilots to production systems of record—and want evaluation to be a strength rather than a risk—let’s talk.
Five Questions to Ask Your AI Vendor (Due Diligence Checklist)
- Can you show correlation with CSAT? If not, it’s a vanity metric.
- Can we export our data? Demand portability.
- How do your metrics benchmark to industry standards?
- Who validates your AI’s accuracy? Independent audits only.
- What’s our exit strategy? Keep CSAT as the fallback.

